Mark: Well, thank you, Lisa. I couldn’t be more excited than to share a little bit more about Zen 3, and our progression to get here. It’s been quite a journey. We set a course over five years ago to design a family of high-performance x86 CPUs. Our goal, very simply: outright leadership. We set up the team so that development of multiple processor generations could be done in parallel — with designers leapfrogging from one generation to another. This has resulted in consistent delivery to the market, as promised.

I could not be more proud than to help unveil our 3rd-Generation of Zen Core debuting in Ryzen desktops this Fall. It is a beast in performance and will deliver absolute leadership in the x86 market.

Zen brought us back and a high performance with a 52% improvement in instruction for clock in a single generation. It built a strong base for us to build upon as we develop the Zen family.

Last year, Zen 2 brought double-digit percent increase in instruction per clock and debuted 7-nanometers in chiplet technology.

That 7-nanometer efficiency enabled leadership multi-core performance and core density. The innovative triplet implementation allowed us ease of manufacturing with the small 7-nanometer dye in scalability to leadership core counts. And now Zen 3.
Wow. What a great job by the design team to improve every aspect of the CPU, delivering leadership performance in that same 7-nanometer node.
Higher frequency, higher Instructure per clock with design improvements across all of the CPU components and lower latency. On top of that, you look at some of the key elements. There’s a new layout of our processor that brings all the cores onto a unified 8-core complex, and that accelerates core-to-core communication. That’s especially helpful for gaming workloads.

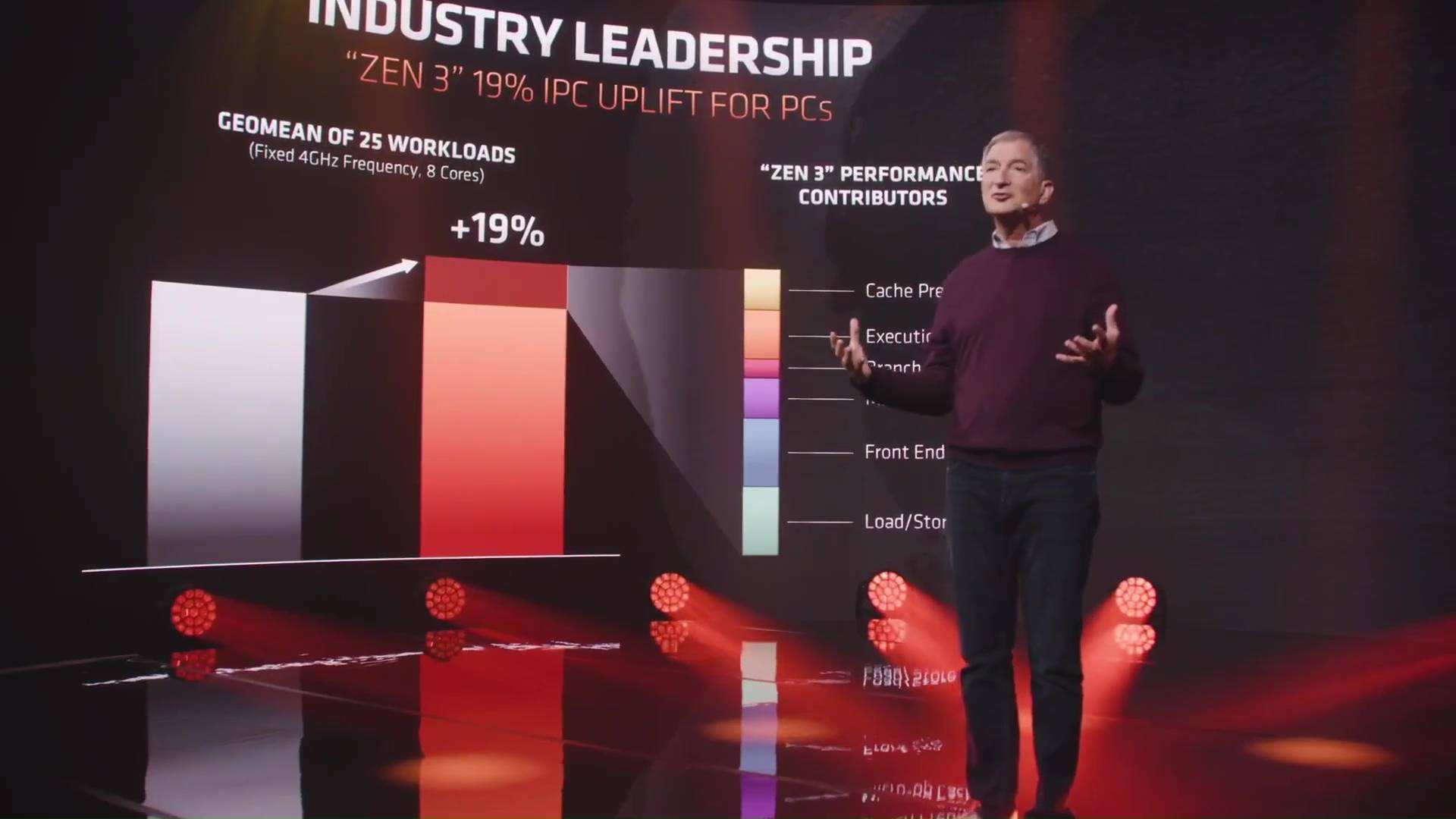
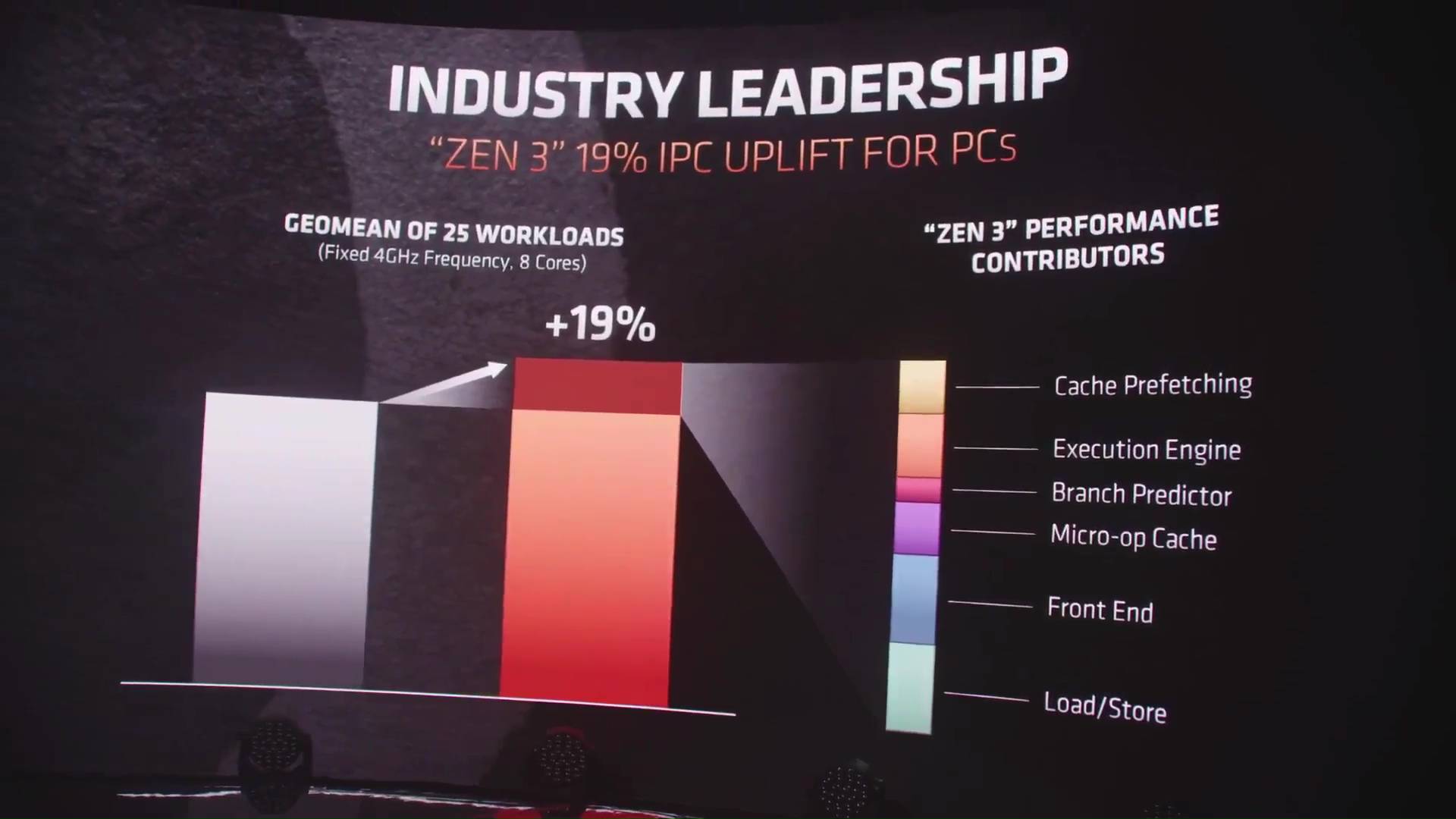
That consolidation actually allows every Core to directly access the 32MB of L3 Cache; and that dramatically accelerates workloads that are latency sensitive, like gaming; and finally, significant changes throughout the Zen 3 architecture generating a 19% instruction per clock uplift.
That’s on top of the significant gains that we had just in the middle of last year with Zen 2. Altogether, Zen 3, as our most significant architectural update yet across the Zen family, we made the Zen 3 floating-point and **inter-direct occlusion**(sp) units wider, more flexible, and allows us to deliver more execution capability to the user at a lower latency.
We’ve increased the number of loads and stores that we can do versus Zen 2, helping us feed those wider execution capabilities in Zen 3.
We’ve added more branch prediction bandwidth. It allows entry to tackle back-to-back predictions much more quickly. Reducing the delays. We call it “Zero Bubble.”

These innovations keep Zen 3 ahead of the industry norm, generational improvements and position Zen 3-based Ryzen to be a clear desktop performance leader. Microprocessor performance engineering never has one single bullet. It takes focused microprocessor engineering. It’s a broad set of improvements that are needed to make a great architecture.

It takes innovation on all of the key levers. Zen 3 is a total front-to-back redesign. The micro architecture had to laser focus on performance and every element, end-to-end improvements. The caching Load/Store. Our execution units. Our Cache Prefetching. Our dispatch. Our decode.
Zen 2, in fact, had been organized with two 4-core Cache complexes, and it was tightly integrated.

Uh, that was a very good design. But what we found is that we brought that together into that single unified cache core complex, and then we brought that direct access to 32MB at L3 Cache rather than the 16MB that we had with Zen 2. That direct access to a cache pool of this size is very significant for gaming.
They tend to make frequent use, of course, of the memory subsystem. And in fact, many games have a dominant thread; and that makes a specially heavy use of the cache. And that thread now sees effectively twice the L3 Cache in Zen 3. So every core can now communicate directly to the cache without traversing across the dye.
And that reduces latency; and it stays synchronized for applications using AI, audio, physics, and more. You can see that we continue our relentless commitment to energy efficiency with every generation. We’re always honing our design methodologies to focus on performance per watt, even as we make the processors faster for gamers.

Zen 3 is no different delivering up to 24% improvement in power efficiency versus the prior generation. That’s double digit performance per watt uplift in the same process node. And that’s on top of all the architectural changes that we drove in to drive up the performance. Our commitment to energy efficiency across time has put us in the driver’s seat today.

Today we’re more than 2.8x more efficient than competing high-end desktop processors. And that’s only a strengthening of the leadership that we demonstrated during the prior Zen 2 era.

We will not let up going forward. We’re focused on execution. Zen 3 is shipping as promised in the 5-nanometers Zen 4 on track in design.
The AMD team is hitting on all cylinders and there’s no shortage of innovations for the next generation of Zen processors to keep AMD in the forefront, and deliver the best compute experience for our customers. Thank you. And let me welcome back Lisa, to now show off our Zen 3 and new Ryzen processors.

Hope you enjoyed this article. Please, support Blizzplanet via PayPal, and follow us on Twitter, Facebook, YouTube, and Twitch for Blizzard games news updates. |
 |










